These notes accompany the Stanford CS class CS131, Computer Vision: Foundations and Applications. This is a development space for the class notes where you can commit your changes as your team builds the notes for your assigned lecture, and once you’re down we will merge your notes onto the finished website.
Head over to https://github.com/ANarcomey/cs131_notes_dev to see the code that creates these web pages!
Steps to create your own notes
To begin writing your own notes that will appear on a website like this, have one team member fork the repository building this web page and configure the fork to build a web page for your team to develop on!
- Step 1: Fork the repository: Fork this repository https://github.com/ANarcomey/cs131_notes_dev into your own GitHub account
- Step 2: Enable GitHub Pages: Enter settings from the menu bar in your forked repo, find the “GitHub Pages” heading, and choose the defaults of “master” branch and “root” directory so that your settings look like the figure below, except “anarcomey” will be replaced with the github username of the team member who created the fork. Don’t worry about choosing a theme or any other settings, we’ve configured that all for you.

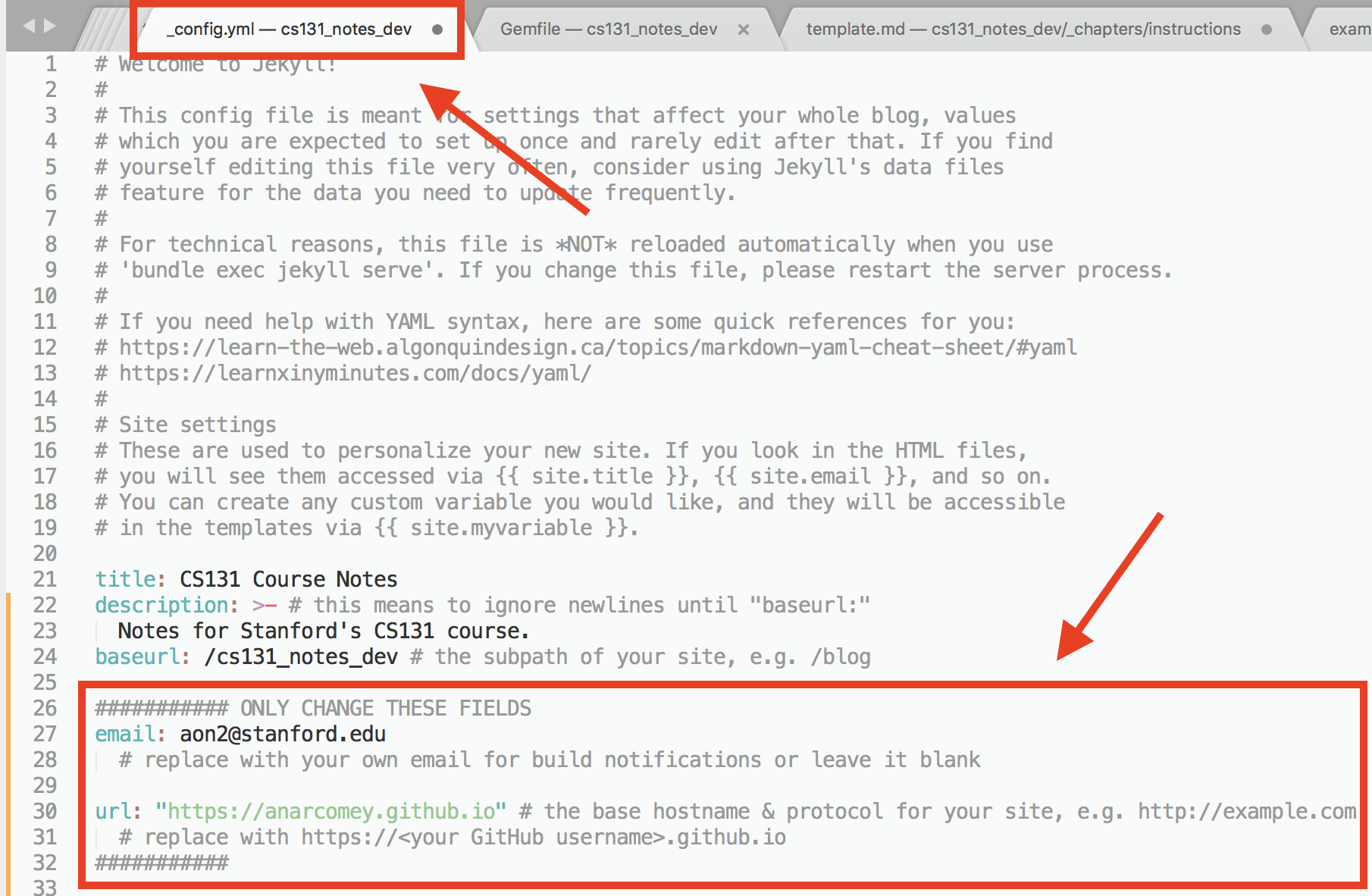
- Step 3: Link the repository to your GitHub Page: In your forked repository, edit the file
_config.yml. Update theurlfield tohttps://your_github_username.github.ioand either remove theemailfield or set it to one of your team members emails if you want to receive build updates by email.
- Step 4: Submit: Create a group Gradescope submission with all of your teammates and submit the url of your GitHub Page containing your notes (e.g.
https://your_github_username.github.io/cs131_notes_dev/and the url of your repository (e.g.https://github.com/your_GitHub_username/cs131_notes_dev).
Steps to update your notes
Now that your notes are live in your own GitHub fork and running at https://your_github_username.github.io/cs131_notes_dev/, you’ll want to add content and update them. To do that, find the Markdown file for your lecture in the _chapters directory and edit the .md file. Once you’ve made your desired updates and want to see what they look like online, commit and push your changes to the master branch. The newly pushed code will render online in ~< a minute and you can see your notes! Once you have a handle on the basic mechanics of Markdown, you can write most of your notes without having to push code and render very often. Take a look at some examples and a template with Markdown guidance in the Intructions module of the website, and also look at the markdown code creating those pages in the .md files in _chapters/instructions.
Since you’re working in groups and editing the same Markdown file, it might make things easier to collaboratively edit a shared document. Here is a list of useful collaborative Markdown editors (link), but you’re free to use any tools or collaboration structures you wish! Much more of the work in making these notes is figuring out what you want to say about the course content rather than messing with Markdown syntax, so you can get write a lot as a group in the collaborative editor before committing to your repository and seeing the rendered result.
Reach out on Piazza with any technical difficulties and we will be happy to help!
Module 0: Instructions
Module 1: Pixels
-
Images and transformations
(insert comma-separated keywords here) -
Filters and convolutions
(insert comma-separated keywords here) -
Edge detection
(insert comma-separated keywords here) -
Features and fitting
(insert comma-separated keywords here) -
Feature descriptors
(insert comma-separated keywords here)
Module 2: Images
-
Image models and priors
(insert comma-separated keywords here) -
Color
(insert comma-separated keywords here) -
Segmentation
(insert comma-separated keywords here) -
Clustering
(insert comma-separated keywords here) -
Resizing
(insert comma-separated keywords here)
Module 3: Recognition
-
Visual recognition
(insert comma-separated keywords here) -
Visual bag of words
(insert comma-separated keywords here) -
Detecting objects by parts
(insert comma-separated keywords here)
Module 4: Videos
Module 5: Cameras
-
Pinhole, computationational, and corner cameras
(insert comma-separated keywords here) -
Camera parameters and stereo
(insert comma-separated keywords here)